在数据驱动决策的时代,企业面临着海量数据存储与处理的挑战。作为国内领先的数据处理服务提供商,友盟+近期首次公开其如何应对超级体量数据的存储与加工,以高效服务超过150万APP和710万网站。这一揭秘不仅展示了友盟+的技术实力,也为行业提供了宝贵的实践经验。
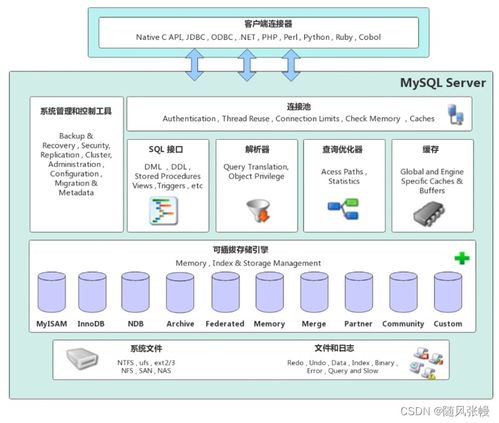
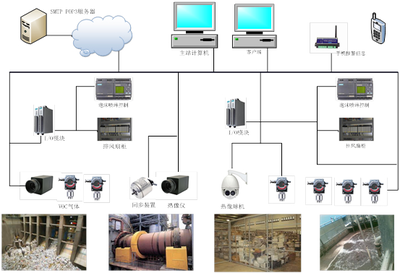
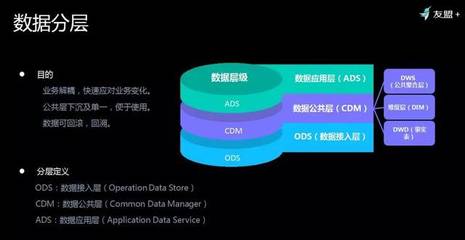
友盟+在数据存储方面采用了分布式存储架构。面对每天产生的PB级数据,传统集中式存储系统难以满足需求。友盟+通过构建多副本、高可用的分布式文件系统,确保数据的安全性和可靠性。同时,结合冷热数据分离策略,将频繁访问的热数据存储在高速存储介质中,而冷数据则迁移至成本更低的存储层,既提升了访问效率,又优化了成本结构。
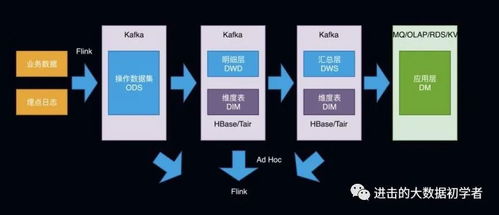
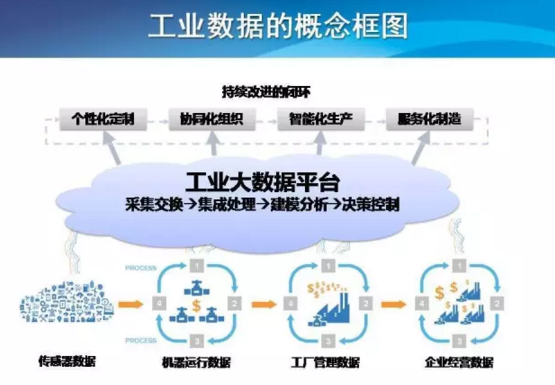
在数据加工环节,友盟+引入了流式处理和批量处理相结合的技术框架。对于实时性要求高的数据,如用户行为日志,友盟+使用实时流处理引擎,实现毫秒级的数据采集、清洗和聚合。而对于历史数据的深度分析,则通过分布式计算平台进行批量处理,支持复杂的数据挖掘和机器学习任务。这种混合处理模式确保了数据处理的高效性和灵活性,满足了不同场景下的业务需求。
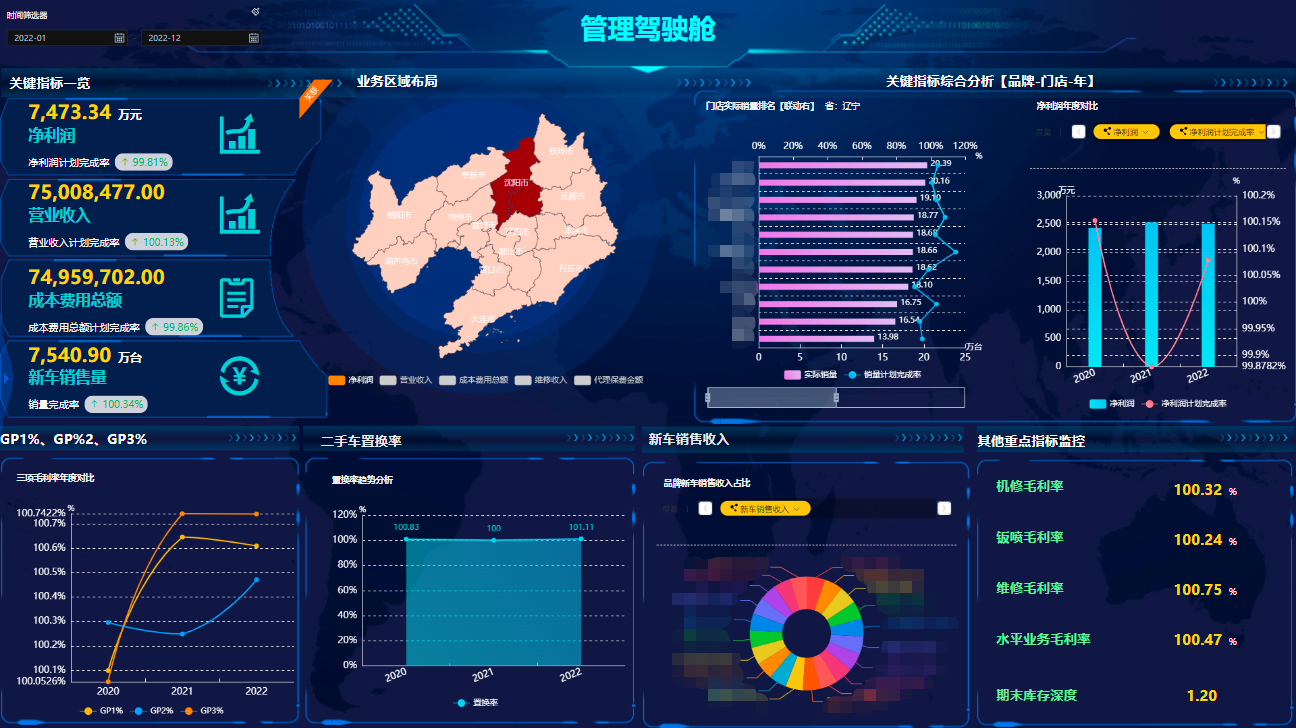
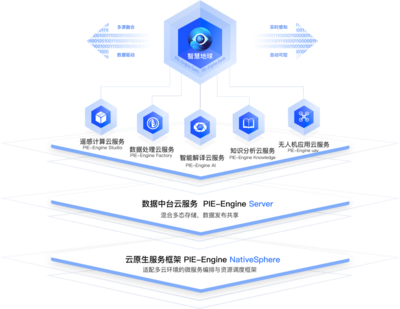
友盟+注重数据服务的智能化和自动化。通过构建统一的数据管道和API接口,友盟+能够将加工后的数据快速交付给客户,支持实时监控、报表生成和个性化推荐等功能。自动化运维工具的应用,进一步降低了系统故障风险,提升了服务的稳定性和可扩展性。
友盟+的成功实践表明,面对超级体量数据,关键在于采用先进的分布式技术、优化数据处理流程,并持续创新服务模式。这不仅帮助150万APP和710万网站实现了数据价值的最大化,也为整个行业树立了标杆。未来,随着5G和物联网的普及,数据处理服务将面临更多挑战,友盟+的经验无疑为行业提供了重要参考。