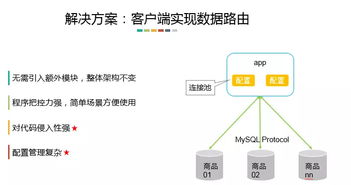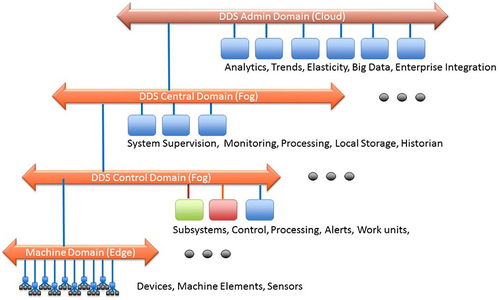
随着车联网产业的快速发展,中台架构已成为支撑海量车端数据高效处理与分析的核心。数据处理服务作为车联网中台的关键组件,其架构设计的优劣直接决定了数据价值挖掘的深度与业务响应的敏捷性。本文将对市场上六款主流的车联网中台数据处理服务架构产品进行对比分析,旨在为技术选型与架构设计提供参考。
一、 核心架构理念对比
- 产品A(云原生一体化平台):强调全栈云原生,基于Kubernetes容器化编排,实现数据处理微服务化。其优势在于弹性伸缩与高可用性,但技术栈较为复杂,对运维要求高。
- 产品B(流批一体数据湖仓):以数据湖仓为核心,统一存储原始数据与处理后的结构化数据,支持流式与批处理一体化。优势在于数据治理与历史回溯能力强,实时性略逊于纯流处理架构。
- 产品C(边缘-云协同计算):采用分层架构,在车端/路侧边缘节点进行初步过滤与聚合,云端进行复杂分析与建模。优势在于降低带宽成本、提升实时响应,但边缘节点管理是一大挑战。
- 产品D(领域驱动智能管道):以业务领域(如驾驶行为、电池健康)为核心组织数据处理流水线,内置丰富的领域模型与算法。优势在于业务贴合度高、开箱即用,但跨领域扩展灵活性一般。
- 产品E(低代码可视化编排平台):提供图形化界面,通过拖拽方式配置数据源、处理规则与输出目标。优势在于降低开发门槛、提升配置效率,但处理复杂逻辑的能力有限。
- 产品F(开源生态集成方案):基于Apache Flink、Kafka等开源组件进行集成与封装,提供标准化数据管道。优势在于技术开放、成本可控,但需要较强的自主研发与集成能力。
二、 关键能力维度分析
- 吞吐量与实时性:产品A与产品F在吞吐量与毫秒级延迟方面表现优异,尤其适合高并发实时场景(如实时预警)。产品B在批处理任务上更具优势,产品C的实时性依赖于边缘算力。
- 数据治理与质量:产品B与产品D在数据血缘追溯、质量监控与主数据管理方面功能完善。产品E与产品F在此方面通常需要额外开发或集成。
- 算法与智能集成:产品D内置算法最丰富,产品A与产品C通常提供标准的机器学习框架集成接口。产品E可能通过插件市场提供算法组件。
- 部署与运维成本:产品A(云原生)与产品F(开源)的运维复杂度最高,但云原生的弹性可能降低长期资源成本。产品E与产品D作为商业化产品,通常提供更完善的运维支持,但采购成本较高。产品C涉及边缘硬件,总体拥有成本需综合评估。
- 生态兼容性与开放性:产品F开放性最强,产品A、B、C通常对主流云服务与数据源兼容性好。产品D和E可能在特定云或数据格式上存在绑定。
三、 选型建议与
选择车联网中台数据处理服务架构产品,需紧密围绕业务场景与技术战略:
- 追求极致实时与弹性扩展:可重点考察云原生一体化平台(产品A)或成熟的开源集成方案(产品F)。
- 数据资产沉淀与深度分析优先:流批一体数据湖仓(产品B)或领域驱动智能管道(产品D)是更优选择。
- 存在海量边缘数据与带宽约束:边缘-云协同架构(产品C)的价值凸显。
- 追求快速上线与降低开发投入:低代码可视化平台(产品E)能显著提升初期效率。
没有一种架构能适用所有场景。企业应结合自身数据规模、实时性要求、团队技术栈及长期数据战略,进行综合评估与取舍。随着算力网络与AI大模型技术的发展,车联网数据处理服务将向更智能、更自适应、云边端深度融合的方向持续演进。